

One of the greatest gifts that we possess as a species is to express, share and interact with fellow beings. The ability to cultivate any idea and bring out the pearls of innovations, discoveries, and inventions from the oysters of chaotic and complex environments is an achievement second to none – and all this revolves around the fulcrum of ‘language’.
From the early days of human evolution, language has been an indispensable tool. Over time, it bloomed into perplexing spoken and written forms, with underlying rules and structures. With global boundaries getting smaller and the emergence of computers and Artificial Intelligence (AI) in particular, the horizon of knowledge has expanded and continues to do so.

Evolution of AI Models
From symbolic and sub-symbolic interpretations to logic-based inferences to data-driven models, AI has traversed a long way to reach where we are today, and still, we have light years to travel.
During the 1990s, Advanced Analytics started to involve step-by-step logic and instructions coded by developers which are deterministic in nature. Traditional Business Intelligence (BI) and rule-based anomaly detection would fall into this category.
With the advent of Machine Learning (ML), human-crafted features came into focus with supervised learning techniques. Predictions, price optimizations, etc. belong to this area.
Thereafter, Deep Learning started to evolve which prominently focuses on unsupervised learning in which data is fed to create rules and algorithms. Image recognition and autonomous driving are the areas of focus here.
Today, we are in the realm of “Foundation Models” that ingest a massive amount of data to generate new human-like art, texts, images, and videos.
What is a Foundation Model?
According to a 2021 research paper at Stanford Institute for Human-Centered Artificial Intelligence (HAI) – “A foundation model is any model that is trained on broad data (generally using self-supervision at scale) that can be adapted (e.g., fine-tuned) to a wide range of downstream tasks; current examples include BERT, GPT-3, and CLIP.”
The underlying concepts of foundation models are deep neural networks and self-supervised learning, both of which have been in existence for years. However, their enormous scale and scope in the last couple of years have expanded our conception of what can be achievable. For example, the recently launched GPT-4 language model has one trillion parameters. The number of parameters in a language model is an indicator of its ability to learn complex functions and patterns.

Foundation models work through ‘transfer learning’ and ‘scale’. The concept of Transfer Learning involves taking the knowledge learned from one task and applying it to another task. For example, learning to drive a car and then using that knowledge to drive a bus or a truck.
While transfer learning makes foundation models possible, scale makes them powerful. Scale involves the following components:
- Improvements in computer hardware – GPU throughput and memory have increased 10X over the last four years
- Transformer model architecture – Leverages the parallelism of the hardware to train expressive models
- More training data being available
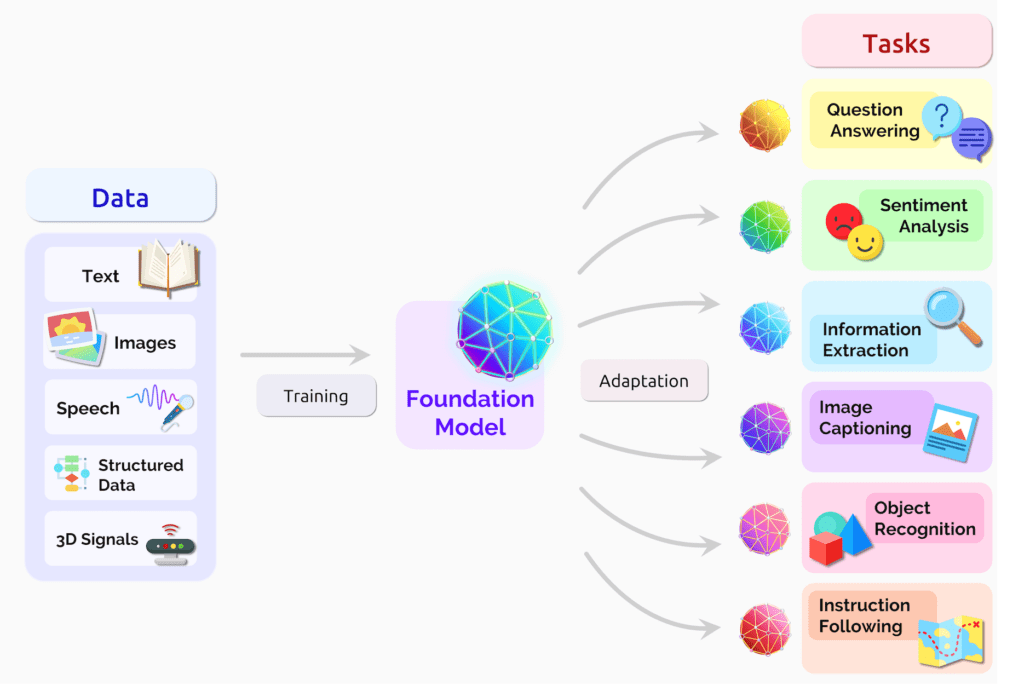
Emergence and Homogenization in Foundation Models
The two key concepts pertaining to the power and versatility of foundation models are – Emergence and Homogenization.
Emergence can be perceived as the appearance of complex patterns and behaviors from the interactions among the underlying components. It refers to the characteristics of a macroscopic system that does not have ay explanation at its microscopic building blocks. For example, water molecules giving rise to waves, lifeless atoms generating living cells, starlings flying together to produce murmurations, etc. These notions do not exist at the fundamental level but ’emerge’ when things accumulate to act as one.

In the case of foundation models, emergence occurs when due to the model’s huge number of parameters and architecture, it can learn relationships between data that are not explicitly labeled. This emergent behavior is key to performing tasks such as language understanding and image recognition.
Homogenization, on the other hand, refers to the process by which the same foundation model can be applied to diverse downstream tasks without compromising on the quality aspects. So, instead of developing a new model from scratch for every new task, a pre-trained foundation model just needs to be fine-tuned with relatively lesser labeled examples. For example, almost all cutting-edge NLP models are now adapted from one of a few foundation models, such as BERT, RoBERTa, T5, etc.
Based on foundation models, researchers have been able to build large-scale AI systems such as Generative AI and Large Language Models (LLMs) to help us find innovative solutions to complex problems and in turn, better understand our physical world.
Furthering Foundation Models: Generative AI and LLMs
Generative AI is a collection of algorithms that can generate seemingly new images, videos, texts, and music while analyzing the pre-trained data. They are built on top of foundation models trained on humongous unlabeled data and can perform a wide range of tasks by identifying the underlying relationships among the components.
For example, GPT (Generative Pretrained Transformer) models, such as GPT-3.5, are foundation models fine-tuned for text summarization, answering questions, sentiment analysis, etc. DALL-E is another foundation model adapted to generate images based on text inputs.

Pre-trained models are ML models that have been trained on a large amount of data before being utilized for a specific task. They can save both time and resources by cutting them down to minimal values while transferring the knowledge to another domain or task.
A type of pre-trained model that has recently gained traction is the Language Model (LM). LMs have the capability to predict the next word or token in the given context. By capturing the syntactic and semantic patterns of natural language, LMs can come up with eloquent, consistent, and comprehensible texts.
A major drawback of traditional language models lies in their limited size of vocabulary and context window length. This hinders their ability to come up with long and diverse texts.
To overcome these limitations, Large Language Models (LLMs) have been created that have mammoth vocabularies and can process immensely long sequences of tokens as well. They are pre-trained on data from diverse sources and domains, such as articles, books, web pages, etc. Having learned from extensive linguistic entities, they can generate texts on various topics and styles.
At a high level, an LLM’s architecture is made up of layers of artificial neurons connected with each other in a complex web. Two components are worth discussing in the context – an encoder and a decoder.

The encoder takes in the input text and transforms it into a high-dimensional vector representation. The decoder takes this representation as input and generates output that may be in the form of classifications, predictions, or generative sequences.
LLMs can be utilized for different Natural Language Processing (NLP) tasks by fine-tuning them on task-specific data or by using them as feature extractors.
Fine-tuning is a process of adjusting the pre-trained model’s parameters by inducing a relatively smaller amount of labeled data for a specific task, such as question answering, summarization, sentiment analysis, etc. This process helps in achieving better results in a shorter period of time as compared to training a model from scratch.
Feature extraction, on the other hand, refers to the process of extracting useful features from a pre-trained model for applying them in a specific downstream task. For example, in image classification, a pre-trained Convolution Neural Network (CNN) can be used for feature extraction by retaining only the feature extraction layers and removing the classification layers. These layers can be applied for extracting features from new images and can even be fed into smaller neural networks to classify the images into particular categories.
Case Study: Predicting the Structure of Molecules using Foundation Models and Large-Scale Language Models
Pretrained models are not only limited to text generation, code writing, and music composition but can also predict the shapes and properties of molecules. According to a recent study conducted at IBM research, there is strong evidence that large-scale molecular language models can encompass adequate chemical and structural information to predict different molecular characteristics including quantum-chemical properties.
Earlier, in order to accurately predict a molecule’s properties by obtaining its 3D shape required extensive simulations or lab experiments. This process took a significant amount of time, ranging from months to years, and was expensive, limiting the availability of the number of detailed structures.
A new AI model belonging to the MoLFormer (Molecular Language transFormer) family of foundation models for molecular discovery has been developed. The best-performing variant has been coined the name MoLFormer-XL.
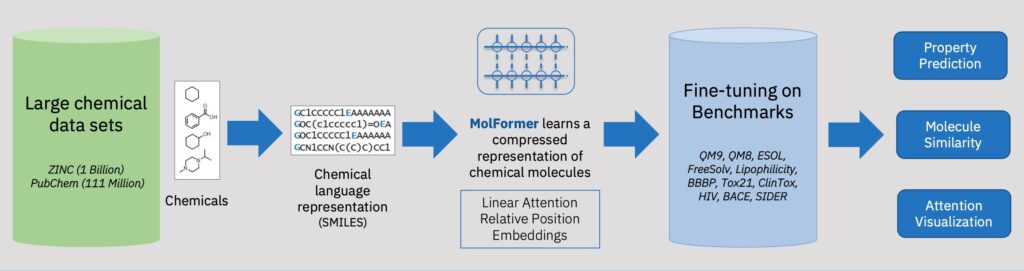
The new model can infer a molecule’s form and structure and can predict its physical, bio-physical, and even quantum-mechanical properties, such as a molecule’s bandgap energies which indicate its ability to convert sunlight into energy.
While traditional molecular models are based on graph neural network architectures predicting molecular behavior from its 2D or 3D structure, MoLFormer-XL relies on more than 1.1 billion molecules (as compared to only 100,000 molecules in the traditional models), each represented by a compact snippet of text belonging to the SMILES (Simplified Molecular Input Line Entry System) notation system.
In NLP, an attention map or specifically an attention mechanism is a part of the underlying architecture that enables the highlighting of relevant features of the input data dynamically. By doing so, neural architectures can automatically weigh the significance of any region of the input and then can take such weights into account for performing the main task.
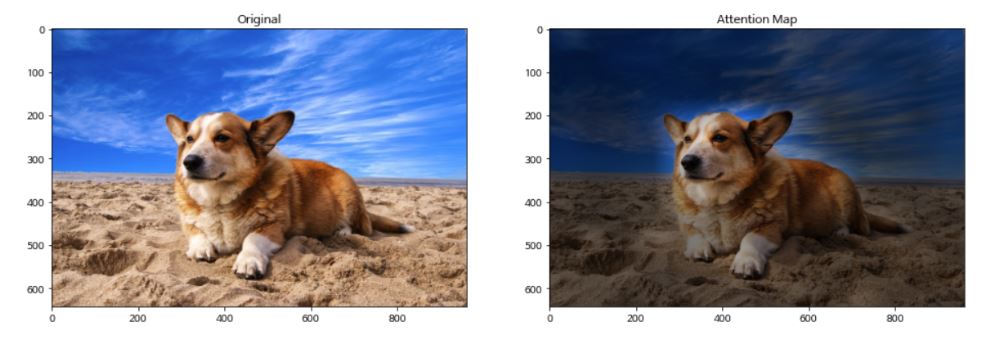
Understanding underlying structures by a model is an emergent behavior. MoLFormer-XL’s attention map reveals the model’s ability to distinguish models by their flavor or blood-brain barrier permeability despite the fact that the model was not even specified about either of the properties. The model focuses on the relative position of atoms in a molecule, learns its structure and properties, and is applicable for screening molecules for new applications or discovering new ones.

MoLFormer-XL’s strength lies in its size and it usually results in enormous computational and energy training costs. But, by implementing an efficient linear time attention mechanism and sorting SMILES strings by length before providing them as input, the per-GPU processing costs rose from 50 to 1600 molecules, thereby drastically reducing the number of GPUs from 1000 to 16. Researchers were able to train a mode in five days and consumed 61 times less energy.
With MoLFormer-XL, researchers can quickly screen a large number of molecules and identify those with the desired properties. This could be groundbreaking in terms of speeding up the drug discovery process, fighting emerging diseases, or even discovering new materials that can accelerate the transition to clean and renewable energy.
Conclusion
Foundation models and LLMs are transforming the field of NLP and beyond. However, significant challenges and risks such as ethical, social, and technical issues do come along and need to be addressed carefully. A detailed topic in itself, I’ll cover them in one of the future articles.
By offering unprecedented capabilities for generating, understanding, and manipulating natural language, as well as transferring knowledge across tasks and domains, we can expect to see even more impressive abilities and applications that will fundamentally transform how we communicate with machines and with each other. With the gift of language and the power of these models at our fingertips, the possibilities for innovation and civilization’s progress are endless.
“No question; language can free us of feeling, or almost. Maybe that’s one of its functions – so we can understand the world without becoming entirely overwhelmed by it.”
― Carl Sagan, Contact
Notes:
- Large-Scale Chemical Language Representations Capture Molecular Structure and Properties
https://doi.org/10.48550/arXiv.2106.09553 - An AI foundation model that learns the grammar of molecules
https://research.ibm.com/blog/molecular-transformer-discovery - Attention in Natural Language Processing
https://doi.org/10.48550/arXiv.1902.02181 - On the Opportunities and Risks of Foundation Models
https://doi.org/10.48550/arXiv.2108.07258
Kindly subscribe to our newsletter to be informed about the articles as soon as they are published.
This article is authored by Abhinav Singh.

Subscribe to Primitive Proton Newsletter
Sign up to keep up to date with the latest news and curated blogs in the world of space, science, and technology.
Your email is never shared with anyone. You can opt out anytime with a simple click!
WE PRIORITISE PRIVACY.